DBA实践:紧扣业务逻辑的水平分表
时至今日,水平分库分表已经成为老话题,尤其是一些数据库相关的公众号最近也发了好几次相关的文章,内容都很全面,而且相当教科书。
只是,通常说别人写文章像教科书,正面看就是写得很专业很详细水平很高,反面看就是太理论不落地脱离业务。
所以我这就不谈理论,只说为什么、做什么和得到了什么。
注:海量数据场景超出本文范围。

笔者:国际认证信息系统审计师、软考系统分析师
实施水平分表的目的可以有很多,但首先要看应用的场景。一般来说单机或单站点的小型集群数据库实施水平分表分库,最大优点就是冷热数据分离,提升热数据的操作访问效率,降低数据库整体运行压力。
如果是分布式集群数据库环境,进一步实现节点之间差异化的水平分表分库,则可以进一步带来优化节点吞吐量、均衡整体运行效率、优化备份过程等等。
但是,实施水平分表是有前提和代价的:要能承受运维工作复杂度增加、数据库的稳定性降低等负面因素,还要充分考虑安全性。
比如我在上一篇:
介绍的就是在水平分表后,数据库表结构调整工作量大增且容易出错,因此需要通过自制工具去减少人为出错的可能性。
水平分表的实施过程离不开分析、设计、实现和测试四部曲。
1、分析,是最重要的,决定了设计、实现和测试的方向
首先要确定是否需要实施水平分表。
实施水平分表与否,关键在于业务运行带来的数据总量、数据增长幅度、热数据比例等因素与单台服务器(单一节点)内存的比例关系。
假设业务系统运行1年才增加1个GB的数据总量,这种系统还搞什么水平分表,除非是为了练手,否则就是折磨自己。
而如果业务系统1年增加1TB数据,其中热数据至少包含2个季度(注意这里是基于时间而不是具体数据量),很显然这很快就会超过了单一节点可以实现的内存上限。如果不实施水平分表,不仅系统查询效率低,而且灾难应对能力更低。
至于比这更大数据量的情况,能折腾海量数据的朋友也不需要看我这文章,所以我这里就不涉及了。
其次是用什么方法进行水平分表。
水平分表方法有多种。除了直接利用数据库系统本身提供的分表(分区)功能之外,基于业务逻辑进行水平分表也是一种常见的做法。
这两种做法的区别在于前者把分表的麻烦事让数据库系统完全接管,而后者则需要对业务数据的情况和数据库的优化措施有足够深入的了解才能实施。
比如,MySQL/MariaDB实现的数据分区功能:
CREATE TABLE ... PARTITION BY ...
属于前者,可以被视为水平分表的一种透明方式。网络上各种介绍文章也很多,相关官方文档可以自行查阅:
https://dev.mysql.com/doc/refman/8.0/en/partitioning-overview.html
但是在笔者的实践中,数据分区功能很难和业务逻辑相联系。透明是透明了,但可控度不行。
而且这功能和数据库平台功能完全绑定,不具备可移植性,不过这个不是这篇文章的重点,只是(我)作为系统分析师必须有所考虑。
典型缺陷场景在于,需要按业务的时间因素实现水平分表时,分区功能并不一定能和业务逻辑相吻合。
有同学或者会说,不就是通过:
PARTITION BY RANGE (YEAR(日期字段))
这样就可以实现按日期逻辑进行数据分区了吗?
对于一般的应用场合这种方法是可以的,但如果需要完全和业务相匹配,就必须认真斟酌。这种做法必须在表内设计一个一旦填写就永远不改的日期时间字段。但是,这个字段中填入的日期时间,并不能简单认定就能等同用于标识业务流程开始的某种意义的日期。虽然这两者差别可能很小,但在业务逻辑叠加数据关系复合强要求时,影响就可能会很大。
具体一点。假设我们需要按“年月”实现水平分表,在业务运行中,该字段填入了某月的最后一天比如1月31日,于是该条数据(或者是它的子表数据)会被分到1月份的数据分区中。
但实际上,业务流程可能因为某种人为因素,被用户设定在2月1日才开始正式启动运行。此时,该条数据实际应该分到2月份的数据分区,这样才能保证热数据按业务逻辑集中。
如果修改该日期字段,则在数据库引擎层面会产生实质性的新数据分区复制插入/旧数据分区删除这样的数据操作过程。这就与数据分区后应该具备稳定性的要求相悖。
MySQL/MariaDB的数据分区功能后来又加入了大量的功能扩充,弥补了早期版本的一些不足,有兴趣可以自行查阅手册。
2、设计
于是最终的选择还是完全靠自己:紧扣业务逻辑,用业务软件的程序逻辑实施水平分表,确保热数据的“热”和业务流程的“热”是完全一致的。
首先是表设计。
在具体设计上,每一张业务信息的主表,都有一个符合业务逻辑的、包含了用于标识业务本身的关键时间信息的字段。
这个关键时间信息,应该是业务运行和统计中最被频繁使用的时间信息,而且一经确定写入数据库就不再修改。比如业务受理时间、结果生成时间等,但一定不能定义为数据记录被INSERT时的时间,即使数值上和业务的时间信息是相等的。
由于日期时间字段操作耗时易错,可以反范式地通过一个冗余字段提高处理速度,该冗余字段可以是字符串或者整数字段。字符串时直接存储日期时间的文本,比如:
日期时间:2023-09-18 10:02:03.052
转为字符串:20230918100203052
注意其中的补零。实际情况下并不需要这么长,一旦确定水平分表的时间跨度后,就只需要存储相应的时间范围即可。比如按年月实施水平分表,则转换为字符串时只需要存储 202309 即可。
如果使用整数类型,可定义为BIGINT类型,存储Unix 时间戳,可移植性要求不那么高时可以直接使用MySQL/MariaDB的 TIMESTAMP 时间戳类型。但时间戳这种方式虽然效率更高,缺点是人难以直读,会增加数据管理的难度。
如下是主表例子:
CREATE TABLE `bizMaster` (
`bizMasterId` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '增量主键',
`bizMasterDateTime` datetime DEFAULT NULL COMMENT '水平分表基于的业务时间',
`bizMasterPeriod` varchar(6) DEFAULT NULL COMMENT '业务日期时间的水平分表格式(YYYYMM)',
PRIMARY KEY (`bizMasterId`),
KEY `BusinessPeriod` (`bizMasterPeriod`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
对主表查询,可以有如下的示范内容:
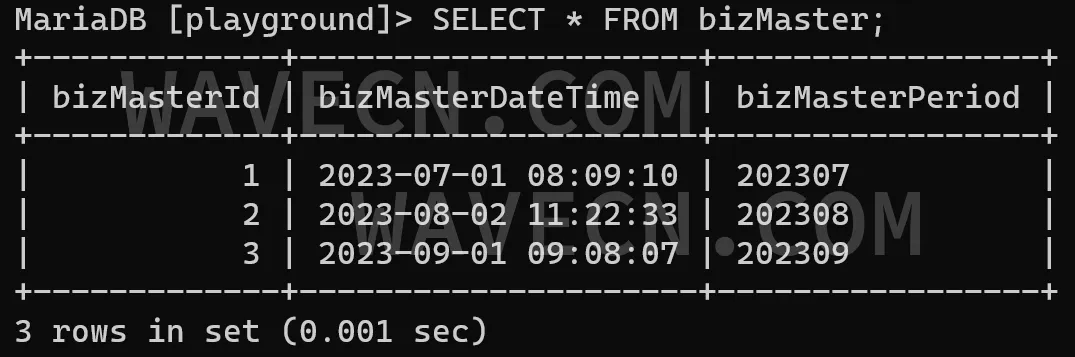
对应到子表的结构,也可以同时具备该日期时间信息字段或转换后的冗余字段,用于数据管理维护,但必要性并不高,且继续反范式地实施数据冗余会提升复杂度和降低可靠性。子表建表命令如下:
CREATE TABLE `bizDetail` (
`bizDetailId` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '子表主键',
`bizMasterId` int(11) DEFAULT NULL COMMENT '主表主键值',
`bizDetailSeqNO` int(10) unsigned DEFAULT NULL COMMENT '子表记录序号',
PRIMARY KEY (`bizDetailId`),
KEY `bizMasterId` (`bizMasterId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
上两个建表命令作为示范只给出必要的字段。其中bizDetailSeqNO和本次话题无关,但业务上需要,所以也列出作为参考,作用就自己推敲了。
这个做法的主要缺点在于不能在主子表之间建立外键关联。但只要所有的数据库操作都细致地使用了数据库事务,外键就并不是必须的。
bizDetail子表实际并不存放数据,而是作为所有水平分表后的数据表的共同模版,所以我在这里为水平分表发明两个词:模版表和平行表。
模版表是只有表结构单不存放数据的表。模版表永远为空,不存放数据,它的作用包括:1)直接和清晰地表述表结构关系;2)作为平行表表结构的基准;3)方便业务流程运行期间据此创建平行表。
平行表是数据被水平分割后实际存放数据的表。平行表的表结构和模版表保持严格一致。如果模版表发生表结构调整,平行表需要同步进行调整。由于在变更表结构时会产生工作量和操作风险,所以我专门自制了工具,可以参考:
里面的介绍。
按我们例子主表的内容,数据库内应该有如下的表:
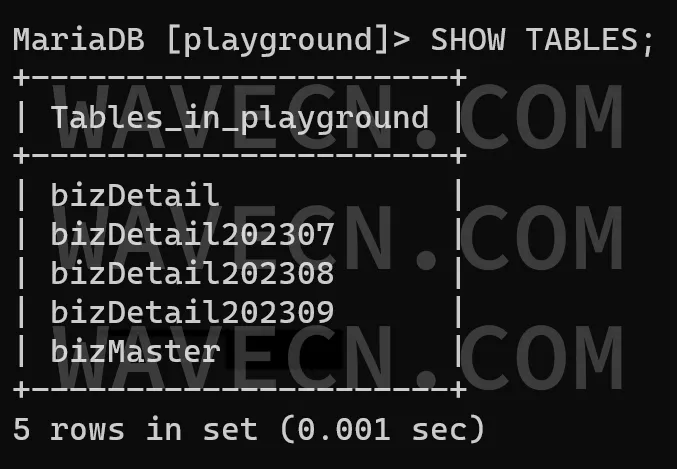
3、实现
在软件开发上,这个水平分表设计需要实现一定的代码量,而且需要通过合适的方法比如封装为数据库访问对象,强制水平表相关的所有数据库操作都受到严格控制。这些操作包括:
1)创建平行表:严格落实只能使用
CREATE TABLE IF NOT EXISTS `库名`.`水平表名` LIKE `库名`.`模版表名`
这样的语法。其中平行表名由前缀和后缀构成,前缀可自行定义,后缀是数据水平分割的时间逻辑要素,比如:bizDetail202309
2)对主表和平行表的数据增删改操作过程确保使用事务,以防出现孤儿数据
3)跨子表查询时,即时动态创建联合视图。比如查询涉及到202307~202309三个月的时间跨度,那么可以如下创建视图然后对视图进行查询:
CREATE VIEW bizViewDetail202307_202309 AS
SELECT * FROM bizDetail202307 UNION ALL
SELECT * FROM bizDetail202308 UNION ALL
SELECT * FROM bizDetail202309
如果需要连接主表查询,可以这样创建视图:
CREATE VIEW bizViewMasterDetail202307_202309 AS
SELECT * FROM bizMaster NATURAL RIGHT JOIN bizDetail202307 UNION ALL
SELECT * FROM bizMaster NATURAL RIGHT JOIN bizDetail202308 UNION ALL
SELECT * FROM bizMaster NATURAL RIGHT JOIN bizDetail202309
创建后的视图可以删除也可以保留,减少反复创建。但如果表结构发生了调整,视图就要在调整表结构时同步删除。
作为示例,可有如下的查询结果:
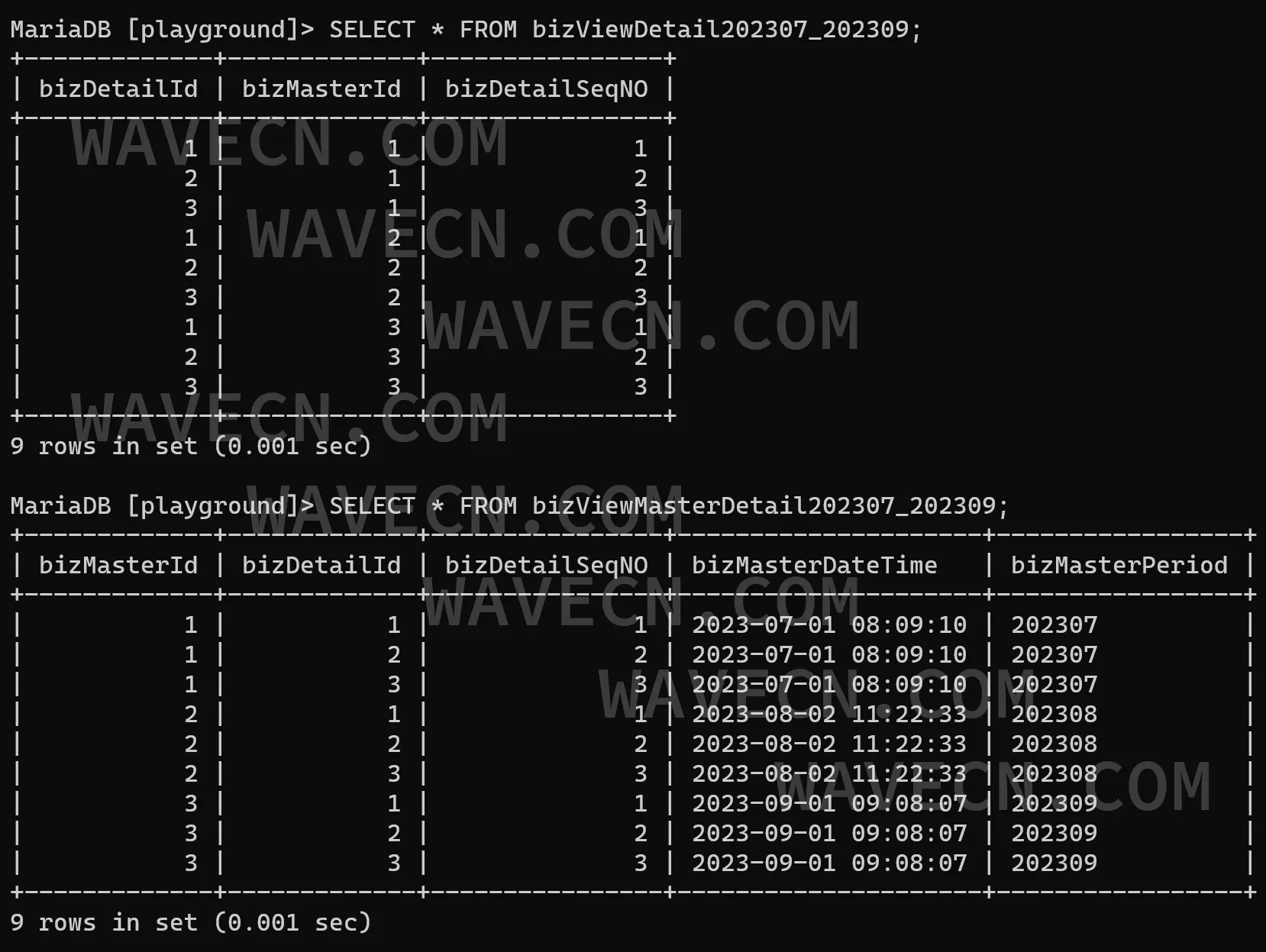
4、测试
测试是个无聊但必要的过程,要消解测试过程的无聊,必须先列出测试清单,确定测试用例等等前置工作,然后用升级打怪的心态去找茬(别人的)......
正经地说,测试重点在于:
1)水平表建表是否正确;
2)数据是否正确插入到了按水平分表逻辑所确定的平行表内;
3)水平表内数据的修改和删除是否能修改和删除正确的记录;
4)在控制下的数据查询、统计所涉及的数据范围是否符合水平分表逻辑,不会查多了水平表,也不会查少了。
最后简单概括一下这种水平分表模式的优缺点。
1、数据库效率:冷热数据分离后,充分利用内存,提高了热数据的查询速度,用户反馈良好。对于必须使用关系数据库,无法应用NoSQL数据库的业务场景比较有用。
2、系统开发:缺点是增加了工作量;优点是因为需要引入各种反人性(懒惰)的开发规范要求而增加了代码的健壮性。结构复杂了,谁还敢不测试就扔给用户。
3、数据库运维:缺点是增加了数据库运维工作量,但DBA的重要性得到了极大的提高(偷笑)。
最后再重复一次:本文所述水平分表方法在于紧扣业务逻辑,如果抛开业务逻辑,在恰当的分区逻辑下直接使用数据库提供的数据分区功能,无疑会大大简化工作量。
只是究竟选择哪一种做法更好,关键首先看业务需求,其次就是打铁自身要够硬,认真学习,考证傍身。
本站微信订阅号:

本页网址二维码: